
Everything that happens in an application or a software system is triggered by something. Whether it’s a user action, a sensor output, a periodic trigger, an event loop, an API call, or something else entirely — our software is governed by events. Sometimes those events are implicit, like a server that handles an HTTP request and updates a database row without ever explicitly defining it as an “entity updated” event or recording the details.

Event-driven architectures formally define the changes that happen as events, and use them directly to power the behavior in software systems. A web browser is the classic, familiar example of this. When the user interacts with the document, events are broadcast openly and used by both the browser and by client-side scripting to react and provide the functionality the user expects.
When we embrace events as the driving force for our application behavior we can use them to take advantage of a variety of benefits like loose coupling, flexible horizontal scaling, strong separation of concerns, granular fault tolerance, and the ability to distribute workloads across multiple independent components. If used thoughtfully, they can help tame intricate workflows and bring disparate systems together.
Keeping up with Complexity
There are a variety of different ways to build event-driven architecture, and several use cases it is well-suited for. There are also many situations where it isn’t a good fit. To determine if it’s the right approach for your project, think about how complex your business logic is and how many other systems you will need to interact and cooperate with. Orienting your behavior around events helps you keep up with complex interactions and stay responsive as you spread your logic out across smaller components focused on particular concerns, making it possible to manage the mischief in your system without keeping the entire global context in your head.
Scenarios that work well within an event-driven approach include:
- E-commerce and inventory management.
- Data collection from a wide variety of sources for AI model training, big-data querying, etc.
- Realtime analytics and monitoring.
- Communication between independent microservices
- Other situations where you’re dealing with a wide variety of inputs from different sources and need to take various actions in response to data changing.
It can really shine in systems that need granular scaling and fault tolerance, keeping errors in one component from impacting others and allowing you to scale different pieces of your application independently. It also provides a lot of flexibility in situations where you don’t have a good understanding of the access patterns or data needs up front and want to iterate on structure without bringing the whole system down.
However, if your system doesn’t need to manage a lot of complexity — like when you just need simple CRUD data entry with straightforward workflows — event-driven architecture may not be a good fit and can introduce unnecessary complexity of its own. It can cause issues when you need immediate synchronous feedback and can’t wait for an event in a queue to be handled. If your application is tightly coupled and your components need to understand each other and have visibility into the workflow, event-driven approaches can make managing dependent steps and failures more challenging.
A Pattern with Many Paths
If you’ve determined that an event-driven workflow would benefit your project, next you need to pick from the wide variety of ways to implement it. The simplest approach is through notifications, where an event producer merely notifies consumers that something has happened. These notifications may carry simple IDs, or they may embed some level of state information along with them so that consumers can act without making a call to the source system.
Taking things a step further, “event sourcing” involves a paradigm shift away from just storing the current state of an entity, instead storing every event that impacted an entity with all of the information needed to re-construct the current state. When changes are made, the entire set of state transformations can be “replayed” to derive the current state and ensure that business logic is applied consistently, even if your structure has changed radically and you care about different attributes this time around. Secondary views or indexes of the data can be derived at any time by reusing historical events.
CQRS (command / query responsibility segregation) is another common pattern used with event-driven approaches, and it separates the system’s write (mutation or command) and read (query) sides, often using events to synchronize data for queries as it is changed. With this approach, read and write operations can easily be scaled independently and multiple specialized views can be derived for various use cases both internal to your team and external across other teams within the organization. You can radically redesign a query store and keep the old version running alongside the new version, updating both while allowing old and new container instances or functions to run at the same time during your rollout
Regardless of how deep you dive into the world of events, event-driven architecture typically involves events published by one or more producers and transmitted through channels like queues or streams managed by an event broker and received by consumers for handling. An event broker might be a programming language event loop or async runtime, a browser queue for triggered events, a streaming event bus like Kafka or Kinesis, a message queue, or something else entirely.
AWS Kinesis for Event Streaming

AWS provides a strong set of tools for many different server-side event-driven approaches, bringing diverse programming language ecosystems and application platforms together with common infrastructure. Kinesis is a data streaming service that provides a good balance of relative simplicity with powerful scaling. It’s able to handle global-scale workloads with consistent performance and reliability, and it doesn’t take an expert to configure and manage.
There are many other platforms available for this same purpose, like Kafka, RabbitMQ, ActiveMQ, and AWS’s own SQS and EventBridge services. They can all power high-performance event-driven architectures, but they each come with their own tradeoffs.
- Kafka is packed with a wide array of control flow features, aggregations, filters, transformations, and high-availability features that make it very powerful, but ultimately more difficult to configure and maintain for more straightforward approaches. Helpful if preventing vendor lock-in is a priority.
- SQS is intended as a more traditional task queue, and if you want to broadcast it to multiple subscribers you must use an SNS fan-out strategy or something similar.
- EventBridge introduces the concept of stream routing, but omits batching, partitioning, and back-pressure.
I prefer Kinesis for many use cases largely because it doesn’t have too many features or options to configure, it implements an opinionated workflow that is great for event-sourcing, and it fits in easily with other AWS tools across the stack. It works well for the kind of one-to-many or many-to-many broadcasting event workflows it is designed for, without requiring a lot of maintenance to keep things running smoothly.
A Global DynamoDB Source of Truth
A strategy that I’ve found very effective on recent projects is to use a DynamoDB table as an immutable event log, streaming events to a serverless “publisher” Lambda function that formats the changes as domain events and broadcasts them over a Kinesis stream for many different listeners. These listeners can be both internal to the project and external within other teams. Since AWS offers a very effective multi-region replication feature with DynamoDB’s global tables, it forms an excellent backbone to keep multiple regions in sync and allow for smooth automatic failover in the event a particular region goes down.
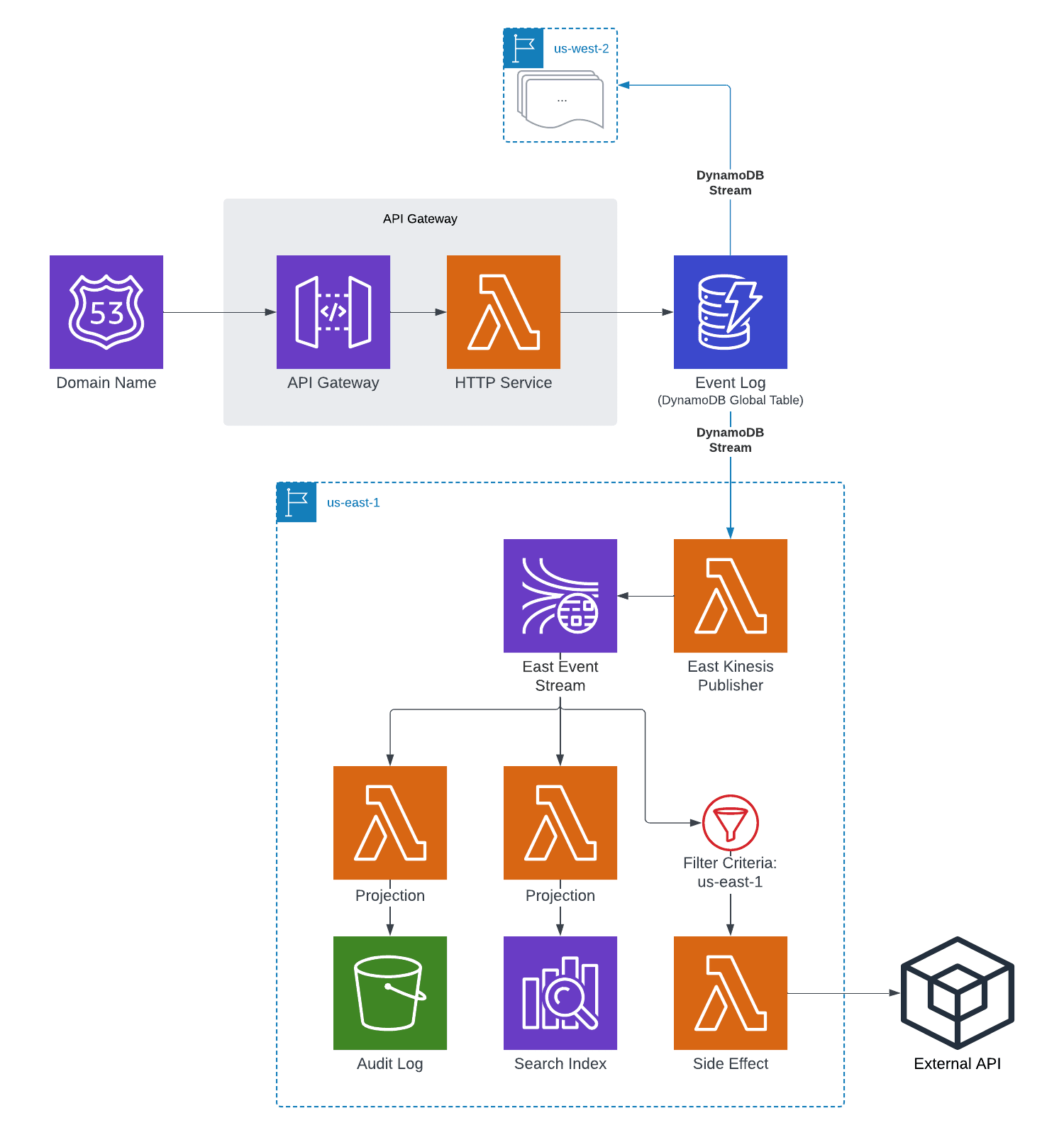
To handle downstream projections or side effects that should only be run once per event, I add the region to the event metadata. I use that metadata in the Lambda event source mapping config to set up a “filter criteria” definition, which ensures that it only handles events that originated from the same region and downstream effects are not duplicated unless intended. In the event of an outage, a load balancer can take a particular region out of rotation and new requests will be routed to active regions.
Putting it all Together
To demonstrate how to configure a real-world API that uses this strategy, I’ve created an example repository using Terraform to deploy a simple CQRS / ES application to API Gateway, using the DynamoDB strategy mentioned above to stream Domain Events to Kinesis and trigger downstream Lambda functions for view projections or other effects. This demo application is implemented using the Rust programming language, but in reality this could be any language that is compatible with the many AWS Lambda runtimes. We’ve built similar high-performance architectures in other languages like Go and TypeScript and seen great results!
Committing Events
To illustrate how, I’ll walk through the configuration and highlight the most important points. To see a demo of the full solution (aside from the multi-region setup), check out the repository on Github.
In my infra/aws folder, I have a reusable config that can be used by Terraform to deploy a particular environment, like “dev” or “prod”. The most important parts are in the infra/modules/app folder, which is a module because it is shared between the aws and local configurations. I use terraform-aws-modules to keep my config relatively concise. First I define a Lambda function to act as the API process:
module "lambda_http_api" { source = "terraform-aws-modules/lambda/aws" function_name = module.label_http_api.id description = "The HTTP API" handler = "bootstrap" runtime = "provided.al2023" publish = true source_path = "../../target/lambda/event-driven-architecture" // ... }
For my Rust application I use the provided.al2023 runtime based on Amazon Linux, and point to the target directory where my Lambda package is built. Your runtime and path may look different depending on your language ecosystem and application platform.
I add some environment variables that my application needs, and then define an “allowed trigger” for API Gateway, allowing the Lambda function to be invoked for HTTP requests:
allowed_triggers = { apigateway = { service = "apigateway" source_arn = "${module.api_gateway.api_execution_arn}/*/*" } }
To allow the API process to commit new events to DynamoDB, I attach a policy statement that provides access to the tables that the application needs. I also configure an assume_role policy that allows API Gateway to work with the Lambda function.
Publishing Events
My application uses an “event-log” table to commit immutable events, which should be broadcast as formatted domain events on my Kinesis stream. This table has a “NEW_IMAGE” DynamoDB stream enabled to power this publishing:
module "dynamodb_event_log" { source = "terraform-aws-modules/dynamodb-table/aws" name = module.label_event_log.id hash_key = "AggregateTypeAndId" range_key = "AggregateIdSequence" stream_enabled = true stream_view_type = "NEW_IMAGE" // ... }
For the Kinesis Publisher Lambda function, I add an event_source_mapping for DynamoDB, allowing the Lambda function to be triggered on new changes:
module "lambda_publisher_kinesis" { source = "terraform-aws-modules/lambda/aws" function_name = module.label_publisher_kinesis.id description = "The Kinesis domain event Publisher" handler = "bootstrap" runtime = "provided.al2023" source_path = "../../target/lambda/publisher_kinesis" // ... event_source_mapping = { dynamodb = { event_source_arn = module.dynamodb_event_log.dynamodb_table_stream_arn starting_position = "LATEST" maximum_retry_attempts = 5 function_response_types = ["ReportBatchItemFailures"] destination_arn_on_failure = module.sqs_publisher_kinesis_dead_letter.queue_arn } } // ... }
The function_response_types definition tells AWS to expect a response with detail about any Batch Item Failures, which is important to ensure that your whole batch isn’t retried on error, potentially duplicating any events in the batch that had already been successfully handled.
When I encounter an error, I return a “Kinesis Event Response” that includes a property for “batch item failures”. This allows me to fail a particular item in my batch and then keep going, only retrying items from the batch that actually failed. This is better than the default functionality that retries the entire batch on error, but if I want to preserve order I need to make sure that I halt processing right away and return all of the identifiers from the events remaining in the batch in addition to the identifier for the failed item.
In order for my Lambda function to work with DynamoDB, I need to attach an extra policy statement providing access to the Lambda function:
module "lambda_publisher_kinesis" { // ... attach_policy_statements = true policy_statements = { dynamodb = { effect = "Allow", actions = [ "dynamodb:GetRecords", "dynamodb:GetShardIterator", "dynamodb:DescribeStream", "dynamodb:ListStreams" ] resources = [module.dynamodb_event_log.dynamodb_table_stream_arn] } // ... } // ... }
In my application code, I check to ensure that the DynamoDB event is an “INSERT”, and then format my domain event so that I can use “put record” to publish the event to Kinesis. To allow this, I need to attach another policy statement providing Kinesis access
module "lambda_publisher_kinesis" { // ... attach_policy_statements = true policy_statements = { // ... kinesis = { effect = "Allow", actions = [ "kinesis:PutRecord", "kinesis:PutRecords" ] resources = [aws_kinesis_stream.event_stream.arn] } } // ... }
Consuming Events
Now, I can add Lambda functions that listen for events and update projected views, add additional training data for a machine learning model and trigger a training round, interact with 3rd-party APIs or other microservices within the same organization, transform and load data into an analytics platform, or do anything else that my application needs to in response to new events.
For my example application, I want to store JSON audit log files in S3 as a backup in case something happens with the events in the DynamoDB table. To do this, I create a “projection-s3-audit” Lambda function. I add an event_source_mapping pointing to my Kinesis stream:
module "lambda_projector_s3_audit" { // ... event_source_mapping = { kinesis = { event_source_arn = resource.aws_kinesis_stream.event_stream.arn starting_position = "LATEST" maximum_retry_attempts = 5 function_response_types = ["ReportBatchItemFailures"] destination_arn_on_failure = module.sqs_projector_s3_audit_dead_letter.queue_arn } } // ... }
This looks nearly identical to the DynamoDB stream configuration, and that’s no coincidence. Kinesis streams are actually built on DynamoDB behind the scenes. They handle scaling, throttling, and retries in largely the same way.
I need to give my Lambda function access to both read from the Kinesis stream and to write to my S3 audit bucket, so I add the policy statements to the Lambda definition. In my application code, I decode the event from the Kinesis payload and save it to the desired folder structure as a JSON file.
With everything in place, when I send a POST to my API Gateway url to create a new Task item, it inserts a new row to my DynamoDB event log.
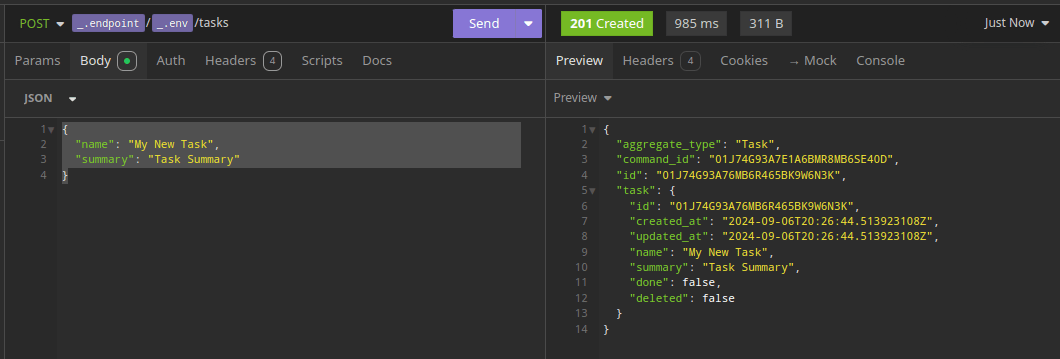
This event triggers my “Kinesis Publisher” Lambda function, which formats it as a domain event and broadcasts it over my Kinesis stream.
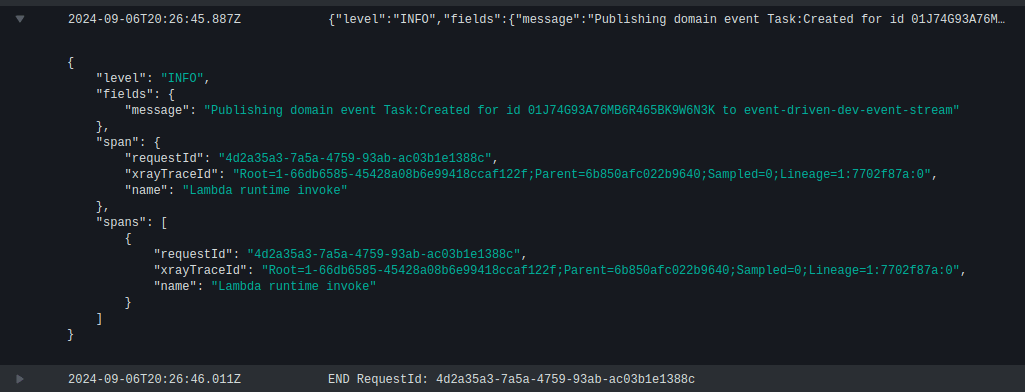
My “S3 Audit Projection” Lambda function is triggered by the Kinesis event and saves the event as a JSON file to my S3 audit bucket.
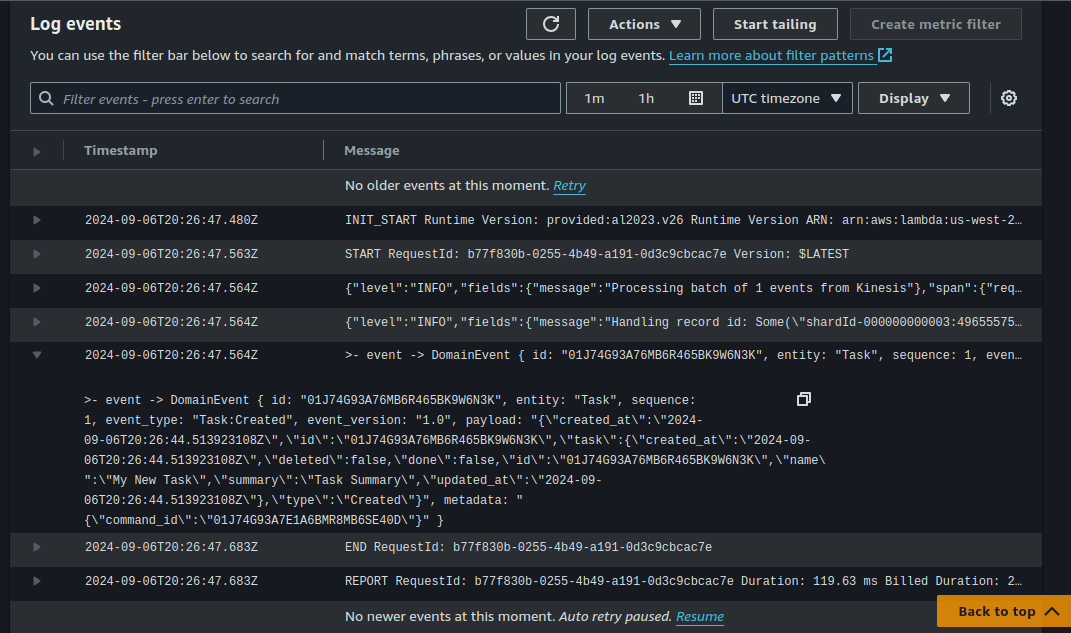
This setup can use “ON_DEMAND” scaling, allowing the resources to horizontally scale automatically to smoothly meet demand with the consistent performance of Amazon’s DynamoDB and Lambda services.
Thoughtful Fault Tolerance
This all sounds well and good, but what about when things go wrong? The key to reliable high-performance systems at large scale is robust fault-tolerance, and this architecture provides a lot of flexibility in how you can isolate your system’s components and recover when things go wrong. You have to be intentional about setting up retry and fallback strategies, however, to make sure you’re prepared for the worst. Think through all of the potential failure points for your application and have a plan for how to recover from incidents of bad behavior or external factors outside of your control.
Retries
The simplest way to automatically recover when event processing fails is to try again. When order is important, however, there are some significant considerations. First of all, when the Lambda event source trigger for Kinesis receives an error, it looks to the trigger config to decide how it should retry. When using the terraform-aws-modules/lambda/aws module as my demo repository does, this is passed in as part of the event_source_mapping definition:
module "lambda_projector_s3_audit" { source = "terraform-aws-modules/lambda/aws" // ... event_source_mapping = { kinesis = { // ... maximum_retry_attempts = 5 // ... } } }
If you’re not using terraform-aws-modules, then you would control this with the aws_lambda_event_source_mapping resource. By default, it will halt the stream and retry infinitely, likely hitting the same error over and over again until some kind of intervention resolves the root cause of the error. This only makes sense if your entire system should be halted until the fault is resolved. With maximum_retry_attemps set, it will only halt the stream until retries have been exhausted, and then it will proceed with later events.
In conjunction with this, another important consideration is how batch size will impact your workflow. If you have a batch size greater than 1, you may end up receiving multiple events for the same entity in the same batch. When something goes wrong, you must decide how to handle the remaining items in the batch. If one event fails for an entity and your Lambda function moves on to other events in the batch, it may process a later event for the same entity out of order. You might solve this by marking not just the current event but all following events in the batch as failed, so that they will all be retried. If the failing event keeps failing, however, then the Lambda event source mapping will see the following events as failing and exhausting their retries, as well. Other ways to solve the issue include keeping track of the entity ID that is failing and only marking following events in the batch as failing if they share the same ID. You could also implement your own manual retry behavior within the Lambda function to manage the logic more directly.
Ultimately, however, it may be best to simply set the batch size to 1 (with the batch_size parameter for the event source mapping config) to take advantage of the built-in Kinesis behavior that halts the stream for that particular event-source mapping until retries have been exhausted.
Out-of-Order Processing
A particularly challenging scenario to work around is when you’re dealing with an unreliable source of events that sends them to you out of order. When this happens, Kinesis’s strict adherence to order can end up causing events to be missed. Consider the following situation: A 3rd-party system sending webhooks delivers an “Updated” event for a particular ID before the “Created” event that it depends on. With a typical SQS queue you can place the failed message back on the queue with a visibility timeout, triggering a retry later on but allowing events behind the failed message to proceed as usual. The “Updated” event would fail and be placed back in the queue, and the Lambda event source trigger would then move on to the next events in the queue, which may include the “Created” event that needs to be processed first. When the “Updated” event is retried, it finds the existing record it expects because the “Created” event was successfully processed in the meantime, and it can now handle the “Updated” event successfully.
In a Kinesis stream, however, batch processing is halted until the retries for the failed events within a batch are exhausted. This means that in the example above, the Updated event will be retried until it reaches the max set in the configuration. Then the event source trigger will move on and handle the “Created” event, but it will never go back to the “Updated” event that failed on its own.
There are multiple ways to work around this. You might use a dead-letter queue (as mentioned below) and set a Lambda function up to trigger when events land in the dead-letter queue so that it can retry out-of-order automatically. This tends to lead to a proliferation of lots of little “retry” Lambda functions with their own dead-letter-queues, however, so if this ordering problem is pervasive you might consider an alternative structure where your internal operations are instead triggered by an SNS notification that fans out events to various SQS queues for each individual internal response to events. This can be done alongside a Kinesis stream intended for easy sharing with external teams.
Dead-Letter Queues
To handle the worst-case scenario where retries don’t work, you can set up a catch-all “dead-letter” queue, which accumulates any failed events that have exhausted their retries. When using the terraform-aws-modules/lambda/aws module, this is also passed in as part of the event_source_mapping definition:
module "lambda_projector_s3_audit" { source = "terraform-aws-modules/lambda/aws" // ... event_source_mapping = { kinesis = { // ... destination_arn_on_failure = module.sqs_projector_s3_audit_dead_letter.queue_arn // ... } } }
When using the aws_lambda_event_source_mapping resource, this is done through a destination_config property.
With SQS workflows, this can be used to “re-drive” events back to the source queue to start all over again once a problem or an outage has been resolved. Kinesis works a little differently, however. The events placed in the dead-letter queue have the “shard iterator” details that you need in order to retrieve the event from the Kinesis stream as long as it is still available. To handle this, you’ll want to set up a Lambda function (triggered manually or on a periodic schedule) that pulls from the dead-letter queue, reads the specified event from Kinesis, and then performs any recovery efforts you need.
You must be careful to consider your Kinesis throughput, however. If you are using on-demand mode, drastic spikes in voleme over the normal traffic that your Kinesis stream handles could be determined by AWS to be suspicious and result in throttling. If you’re using provisioned-concurrency mode, make sure you’ve adjusted your config to handle the amount of load you’re about to place on it. If your events error out again because of Kinesis throttling or other errors, they should go back into the dead-letter queue so that you can try again.
Replaying Events
A common tool in event-driven systems is a way to trigger “replays”, where existing events are re-broadcast on the event stream (or alternatively to a dedicated replay stream) so that specific handlers can pay attention to the replays and re-build their view of the data. This operation is often triggered by a manual build task with options to specify which entity types or IDs should be replayed, and which consumers should pay attention to the replay.
To accomplish such a replay in this system a DynamoDB Scan can be used, optionally filtering by entity types or IDs. Metadata can be used to signal to consumers whether they should pay attention to the replayed events or not. DynamoDB should preserve order within the same partition key using the sort key (the sequence number in my example application).
A Reliable, High Performance Solution
With this configuration, your team can take advantage of a Amazon’s near-infinite capacity for smooth scaling and consistent performance across a globally distributed infrastructure with rich fault tolerance and automatic failover. If your organization uses microservices, they can communicate with each other using events without the need for complicated authentication strategies, relying on AWS’s built-in access control. Diverse teams can bring their own programming language and application platform, and Amazon’s cross-platform tools can unify them all and keep everything in sync in near-realtime.
Taking advantage of the built-in functionality of these tools, your team can achieve a world-class architecture without having to rely on mountains of infrastructure configuration or managing detailed autoscaling rules, and your cost will automatically scale alongside your usage without provisioned capacity sitting idle and going to waste.
Would a distributed, event-driven system like this help your team achieve ambitious goals for global digital transformation? Do you need to tame the complexity of a convoluted workflow, or deal with syncing with an unreliable 3rd-party API without disrupting your whole system when there are failures? Is over-complicated configuration causing your team endless grief as they try to manage a feature-packed enterprise event bus?
A streamlined event-driven architecture based on AWS tools like DynamoDB and Kinesis might be just what you need to simplify your codebase and take advantage of Amazon’s powerful and resilient infrastructure without needing a fleet of DevOps or Site Reliability Engineers to manage it. Nearform can help you craft highly maintainable solutions with outstanding performance and the security and reliability you expect from AWS, giving your team the tools and the training they need to succeed.
Contact us today to find out how we can accelerate your team and deliver amazing applications!
